
Tag: XML

XXE es una vulnerabilidad en el procesamiento de XML, un texto que está marcado según reglas específicas
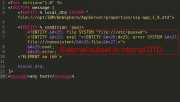
This little technique can force your blind XXE to output anything you want!
XXE es una vulnerabilidad en el procesamiento de XML, un texto que está marcado según reglas específicas
This little technique can force your blind XXE to output anything you want!